通过检查 Nsight 系统中的并发和并行 Numba CUDA 代码了解性能分析。
介绍
优化是编写高性能代码的关键部分,无论你是在编写 Web
服务器还是计算流体力学模拟软件。分析功能可让你对代码做出明智的决策。从某种意义上说,没有分析功能的优化就像盲目飞行:对于拥有专业知识和敏锐直觉的经验丰富的专业人士来说,这基本上没问题,但对于几乎所有其他人来说,这都是灾难的根源。
在本教程中
在我最初的系列 Numba
CUDA 示例 (参见第 1 、2 、3 和 4
部分)之后,我们将研究未经优化的单流代码与使用流并发和其他优化的稍好版本之间的比较。我们将从头开始学习如何使用英伟达 Nsight
系统 来剖析和分析 CUDA 代码。本教程中包含 5 段代码,所有代码都可以在
https://colab.research.google.com/drive/1dY6l4HOfQwzmnbdzZRw6z0Lpb9FN1kM3?usp=sharing
中找到。
Nsight 系统
NVIDIA 建议最佳实践是遵循APOD
框架 (评估、并行化、优化、部署 )。有各种专有、开源、免费和商业软件可用于不同类型的评估和分析。资深
Python
用户可能熟悉基本分析器,例如、cProfile,line_profiler,memory_profiler(不幸的是,截至
2024 年已不再维护)和更高级的工具,例如PyInstrument 和Memray 。这些分析器针对“主机”的特定方面,例如
CPU 和 RAM 使用情况。
但是,分析“设备”(例如
GPU)代码及其与主机的交互需要设备供应商提供的专用工具。对于 NVIDIA
GPU,Nsight Systems、Nsight Compute 和 Nsight Graphics
可用于分析计算的不同方面。在本教程中,我们将重点介绍如何使用 Nsight
Systems,这是一个系统范围的分析器。我们将使用它来分析通过 Numba CUDA 与
GPU 交互的 Python 代码。
首先,你需要 Nsight Systems CLI 和 GUI。CLI 可以单独安装,用于在支持
GPGPU 的系统中分析代码。完整版包括 CLI 和
GUI。请注意,这两个版本都可以安装在没有 GPU 的系统中。从 NVIDIA
网站 获取你需要的版本。
为了更容易在 GUI 中可视化代码段,NVIDIA 还提供了 Python
pip和conda-installable
库nvtx,我们将使用它来注释代码段。稍后将详细介绍。
设置一切:一个简单的例子
在本节中,我们将设置开发和分析环境。下面是两个非常简单的 Python
脚本:kernels和 run_v1。前者将包含所有 CUDA
内核,后者将作为运行示例的入口点。在此示例中,我们遵循文章CUDA by Numba
示例第 3 部分:流和事件 中介绍的“reduce”模式来计算数组的总和。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import numbafrom numba import cuda256 32 * 40 @cuda.jit def partial_reduce (array, partial_reduction ):1 )0.0 )for i_arr in range (i_start, array.size, threads_per_grid):2 while i > 0 :if tid < i:2 if tid == 0 :0 ]@cuda.jit def single_thread_sum (partial_reduction, sum ):sum [0 ] = numba.float32(0.0 )for element in partial_reduction:sum [0 ] += element@cuda.jit def divide_by (array, val_array ):1 )1 )for i in range (i_start, array.size, threads_per_grid):0 ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import argparseimport warningsimport numpy as npfrom numba import cudafrom numba.core.errors import NumbaPerformanceWarningdef run (size: int ):print (f"Old sum: {a.sum ():.3 f} " )1 ,), dtype=dev_a.dtype)1 , 1 ](dev_a_reduce, dev_a_sum)print (f"New sum: {a.sum ():.3 f} " )def main ():0 ]]'Simple Example V1' )"-n" ,"--array-size" ,type = int ,100_000_000 ,"N" ,help = "Array size"
这是一个简单的脚本,可以直接运行:
1 2 3 ---sum : 100000000.000 sum : 1.000
我们还通过分析器运行了这段代码,这只需要在调用脚本之前调用带有一些选项的
nsys,假如我们在本地将其分别保存为Kernels.py和run_v1.py
,然后执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ nsys profile \all \0 : General Metrics for NVIDIA TU10x (any frequency)sum : 100000000.000 sum : 1.000 '/tmp/nsys-report-fb78.qdstrm' 1 /1 ] [========================100 %] profile_run_v1.nsys-rep
⚠️ 注意:
保存为文件在 run_v1.py中需要引入 Kernels.py
中的方法和变量:
1 2 3 4 5 6 7 from kernels import (
你可以查阅 Nsight
CLI 文档:
https://docs.nvidia.com/nsight-systems/UserGuide/index.html ,了解
nsys CLI
的所有可用选项。在本教程中,我们将始终使用上述选项。让我们来分析一下这条命令:
导航 Nsight 系统图形用户界面
如果命令成功退出,我们将在当前文件夹中找到
profile_run_v1.nsys-rep。我们将通过启动 Nsight 系统图形用户界面(文件
> 打开)打开该文件。初始视图略显混乱。因此,我们首先要整理一下:将
"事件视图 "端口调整到底部,并将 "时间轴视图 "端口下的 CPU、GPU
和进程最小化。现在只展开
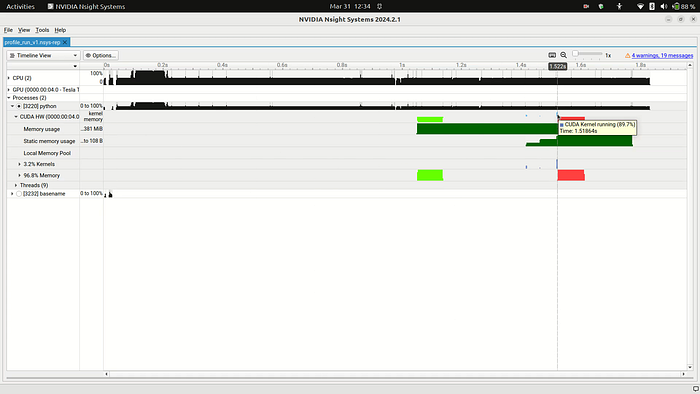
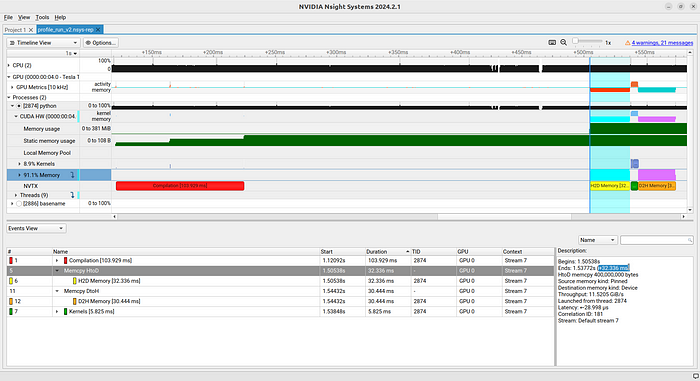
Processes > python > CUDA HW。请参见图 1a 和图
1b。
首先,让我们找到内核。在 CUDA HW
一行,你会发现绿色和红色的圆球,以及极小的浅蓝色片段(见图
1b)。如果将鼠标悬停在它们上面,就会看到工具提示,红色和绿色的提示是
"CUDA 内存操作正在进行中",浅蓝色的提示是 "CUDA
内核正在运行(89.7%)"。这些将是我们分析的主要内容。通过这一行,我们可以了解内存传输的时间和方式(红色和绿色),以及内核运行的时间和方式(浅蓝色)。
让我们再深入研究一下我们的内核。你会看到三个非常小的蓝色片段,每个片段代表一个内核调用。点击并拖动鼠标,从第一个内核调用开始前拖动到最后一个内核调用结束后,然后按下
Shift + Z 键,即可放大该区域。
现在我们已经找到了内核,让我们来看看一些指标。为此,我们打开
GPU > GPU Metrics
选项卡。在这个面板中,可以找到计算内核的 "Warp Occupancy( warp
占用率)"(米色)。优化 CUDA 代码的一种方法是确保 warp
占用率在尽可能长的时间内接近 100%。这意味着我们的 GPU
不会闲置。我们注意到第一个和最后一个内核会出现这种情况,但中间的内核不会。这在意料之中,因为中间内核启动的是单线程。本节最后需要注意的是
"GPU > GPU Metrics > SMs Active > Tensor Active / FP16 Active"
行。该行将显示是否正在使用张量内核。在这种情况下,你应该确认它们没有被使用。
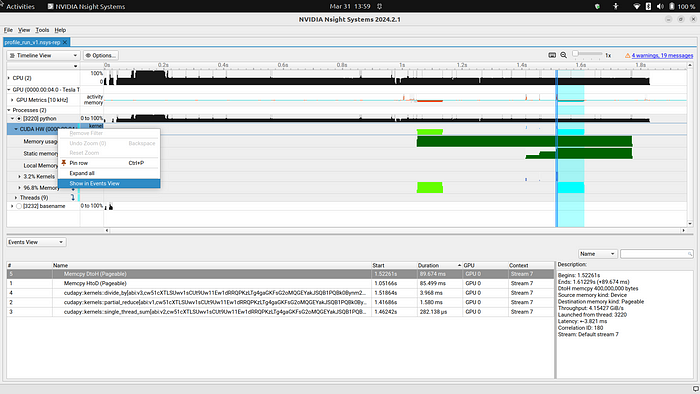
现在让我们简要查看一下事件视图。右键单击
Processes > python > CUDA HW,然后单击 "Show in
Events View (在事件视图中显示)"。然后按持续时间从长到短排序。在图 3
中,我们可以看到最慢的事件是两次可翻页内存传输。我们在《CUDA by Numba
示例第 3
部分:流与事件 》中看到,可翻页内存传输可能不是最佳选择,我们应该优先选择页面锁定或
"钉住"
内存传输。如果由于使用可分页内存导致内存传输速度变慢,那么事件视图就能很好地识别出这些慢速传输的位置。
专业建议:你可以通过右键单击
"Processes > python > CUDA HW > XX% Memory"来隔离内存传输。
在本节中,我们学习了如何分析一个使用 CUDA 的 Python 程序,以及如何在
Nsight Systems GUI
中可视化该程序的基本信息。我们还注意到,在这个简单的程序中,我们使用的是可翻页内存而不是钉式内存,我们的一个内核没有占用所有
warp(即 CUDA 中的线程束) ,GPU
在内核运行之间有相当长的空闲时间,而且我们没有使用张量内核。
使用 NVTX 进行注释
在本节中,我们将学习如何通过使用 NVTX 对 Nsight
系统中的部分进行注释来改善我们的分析体验。NVTX
允许我们标记代码的不同区域。它可以标记范围和瞬时事件。如需深入了解,请查看文档:https://nvtx.readthedocs.io/en/latest/index.html 。我们的Colab
里有一段代码: run_v2, 我们将其在本地保存为
run_v2.py,除了注释 run_v1.py
之外,还更改了这一行:
1 a = np.ones(size, dtype=np.float32)
到这些:
1 2 a = cuda.pinned_array(size, dtype=np.float32)1.0
因此,除了注释外,我们现在还使用了钉状内存。如果你想了解更多有关 CUDA
支持的不同类型内存的信息,请参阅《CUDA
C++ 编程指南:
https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/ 》。值得注意的是,这并不是在
Numba
中钉住数组的唯一方法。之前创建的Numpy数组也可以通过上下文创建,这在Numba文档中有解释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import argparseimport warningsimport numpy as npimport nvtxfrom numba import cudafrom numba.core.errors import NumbaPerformanceWarningdef run (size ):with nvtx.annotate("Compilation" , color="red" ):1 ,), dtype=dev_a.dtype)1 , 1 ](dev_a_reduce, dev_a_sum)1.0 print (f"Old sum: {a.sum ():.3 f} " )with nvtx.annotate("H2D Memory" , color="yellow" ):1 ,), dtype=dev_a.dtype)with nvtx.annotate("Kernels" , color="green" ):1 , 1 ](dev_a_reduce, dev_a_sum)with nvtx.annotate("D2H Memory" , color="orange" ):print (f"New sum: {a.sum ():.3 f} " )def main ():0 ]]"Simple Example v2" )"-n" ,"--array-size" ,type =int ,100_000_000 ,"N" ,help ="Array size" ,if __name__ == "__main__" :
对比这两个文件,你会发现,只需将一些 GPU 内核调用:
1 2 with nvtx.annotate("Region Title" , color="red" ):
专业提示:你还可以通过在函数定义上方放置 @nvtx.annotate
装饰器来注释函数,通过使用 python -m nvtx run_v2.py
调用脚本来自动注释所有内容,或通过启用或禁用 nvtx.Profile()
在代码中选择性地应用自动注释器。请参阅文档:
https://nvtx.readthedocs.io/en/latest/index.html !
让我们运行这个新脚本并在 Nsight 系统中打开结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ nsys profile \all \0 : General Metrics for NVIDIA TU10x (any frequency)sum : 100000000.000 sum : 1.000 '/tmp/nsys-report-69ab.qdstrm' 1 /1 ] [========================100 %] profile_run_v2.nsys-rep
同样,我们先将所有内容最小化,只打开
"Processes > python > CUDA HW"。参见图
4。请注意,我们现在有了一条新线
NVTX。在时间线窗口的这一行中,我们可以看到不同颜色的区块,它们与我们在代码中创建的注释区域相对应。它们分别是
Compilation(编译)、H2D Memory(H2D
内存)、Kernels(内核)和 D2H Memory(D2H
内存)。其中有些区域可能太小,无法阅读,但如果放大该区域,则可以清晰地看到。
分析器确认了这些内存被钉住,从而确保我们的代码真正使用了钉住的内存。此外,H2D Memory
和 D2H Memory
现在所花费的时间不到之前的一半。一般来说,我们可以期待使用固定内存或预取映射阵列(Numba
不支持)能获得更好的性能。
流并发
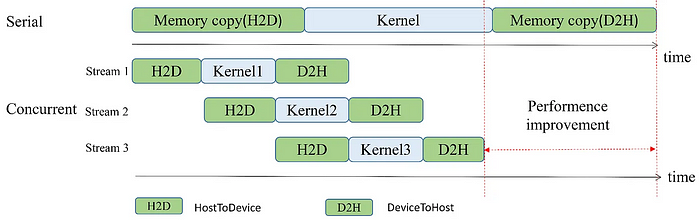
现在,我们将研究是否可以通过引入流来改进这段代码。我们的想法是,在进行内存传输的同时,GPU
可以开始处理数据。这样就可以实现一定程度的并发,从而确保我们尽可能充分地利用经线。
在下面的代码中,我们将把数组的处理分成大致相同的部分。每个部分将在单独的流中运行,包括传输数据和计算数组的总和。然后,我们同步所有流,并求和它们的部分和。此时,我们就可以为每个流独立启动规范化内核。
我们想回答几个问题:
下面的代码真的会产生并发性吗?我们是否会引入错误?
是否比使用单流的代码更快?
warp 占用率是否更好?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 import argparseimport warningsfrom math import ceilimport numpy as npimport nvtxfrom numba import cudafrom numba.core.errors import NumbaPerformanceWarningdef run (size, nstreams ):with nvtx.annotate("Compilation" , color="red" ):1 ,), dtype=dev_a.dtype)1 , 1 ](dev_a_reduce, dev_a_sum)1.0 for i in range (nstreams)]min (s + step, size) for s in starts]print (f"Old sum: {a.sum ():.3 f} " )1 , dtype=np.float32) for _ in range (nstreams)]with cuda.defer_cleanup():for i, (stream, start, end) in enumerate (zip (streams, starts, ends)):with nvtx.annotate(f"H2D Memory Stream {i} " , color="yellow" ):1 ,), dtype=dev_a.dtype, stream=stream)with nvtx.annotate(f"Sum Kernels Stream {i} " , color="green" ):for _ in range (50 ): 1 , 1 , stream](dev_a_reduce, dev_a_sum)with nvtx.annotate(f"D2H Memory Stream {i} " , color="orange" ):sum (cpu_sums)with cuda.pinned(a_sum_all):with nvtx.annotate("D2H Memory Default Stream" , color="orange" ):for i, (stream, start, end, dev_a) in enumerate (zip (streams, starts, ends, devs_a)with nvtx.annotate(f"Divide Kernel Stream {i} " , color="green" ):with nvtx.annotate(f"D2H Memory Stream {i} " , color="orange" ):print (f"New sum: {a.sum ():.3 f} " )def main ():0 ]]"Simple Example v3" )"-n" ,"--array-size" ,type =int ,100_000_000 ,"N" ,help ="Array size" ,"-s" ,"--streams" ,type =int ,4 ,"N" ,help ="Array size" ,if __name__ == "__main__" :
让我们运行代码并收集结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ nsys profile \all \4 0 : General Metrics for NVIDIA TU10x (any frequency)sum : 100000000.000 sum : 1.000 '/tmp/nsys-report-a666.qdstrm' 1 /1 ] [========================100 %] profile_run_v3_4streams.nsys-rep
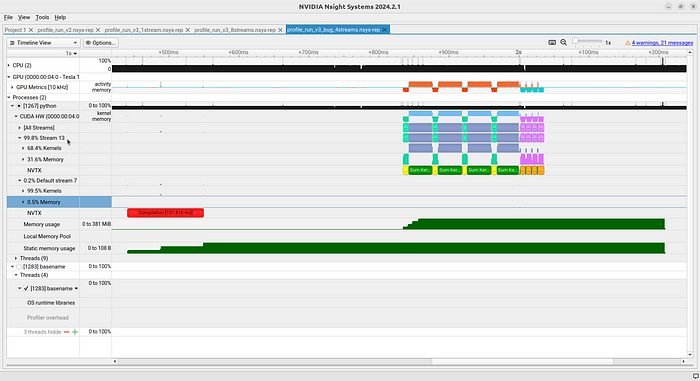
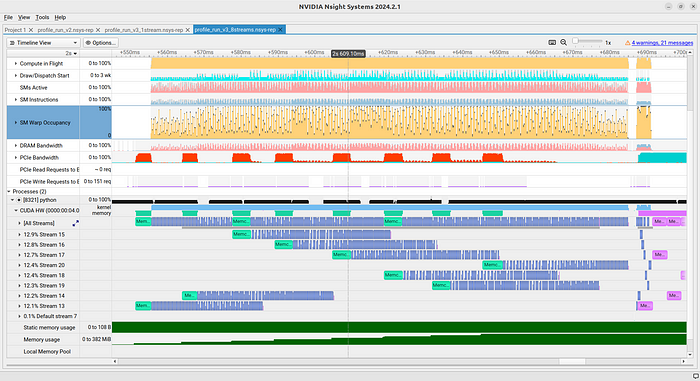
程序运行后得到了正确答案。但当我们打开分析文件时(见图
6),我们会发现有两个数据流,而不是 4
个!其中一个基本上完全处于空闲状态!这到底是怎么回事?
在创建数据流时存在一个错误。通过
1 streams = [cuda.stream()] * nstreams
我们实际上是在创建一个单一的数据流,并将其重复 n
次。那么,为什么我们看到的是两个数据流而不是一个呢?事实上,其中一个流的计算量并不大,这说明有一个流我们并没有使用。这个流就是默认流,我们在代码中完全没有使用它,因为所有
GPU 交互都有一个流,也就是我们创建的流。
我们可以通过以下方法修复这个错误:
1 2 3 streams = [cuda.stream() for _ in range (nstreams)]assert all (s1.handle != s2.handle for s1, s2 in zip (streams[:-1 ], streams[1 :]))
上述代码还将确保它们确实是不同的数据流,因此如果我们在代码中设置了这一功能,它就能捕捉到错误。它通过检查数据流指针值来做到这一点。
现在,我们可以使用 1 个数据流和 8
个数据流运行修正后的代码进行比较。分别见图 7 和图 8。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ nsys profile \all \1 0 : General Metrics for NVIDIA TU10x (any frequency)sum : 100000000.000 sum : 1.000 '/tmp/nsys-report-de65.qdstrm' 1 /1 ] [========================100 %] profile_run_v3_1stream.nsys-rep
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ nsys profile \all \8 0 : General Metrics for NVIDIA TU10x (any frequency)sum : 100000000.000 sum : 1.000 '/tmp/nsys-report-1fb7.qdstrm' 1 /1 ] [========================100 %] profile_run_v3_8streams.nsys-rep
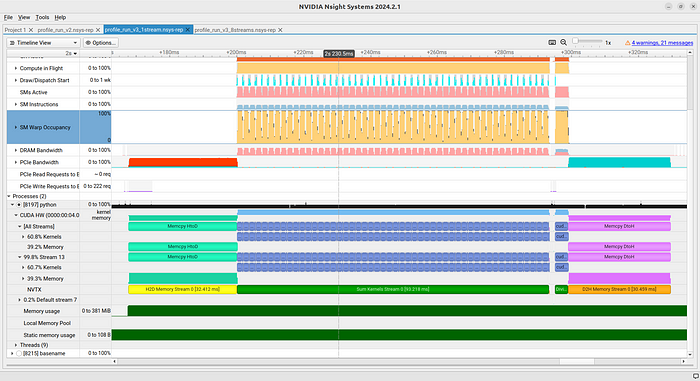
同样,两个结果都是正确的。打开有 8
个数据流的数据流,我们可以看到错误已被修复(图
7)。事实上,我们现在可以看到 9 个数据流(8 个已创建数据流 +
默认数据流)。此外,我们还看到它们同时工作!因此,我们实现了并发!
遗憾的是,如果我们再深入研究一下,就会发现并发代码的速度并不一定更快。在我的机器上,两个版本的关键部分,从内存传输开始到最后一次
GPU-CPU 复制大约需要 160 毫秒。
罪魁祸首很可能是 warp 占用率。我们注意到,单流版本的 warp
占用率明显更高。在这个例子中,我们在计算方面获得的收益很可能因为没有有效占用
GPU
而损失掉了。这可能与代码结构有关,因为代码(人为地)调用了太多内核。此外,如果所有线程都被单个流填满,并发性就不会提高,因为其他流必须闲置,直到资源释放。
这个例子很重要,因为它表明我们对性能的先入为主的概念只是假设。它们需要验证。
目前,我们已经对 APOD
进行了评估和并行化(通过线程和并发),因此下一步就是部署。我们还注意到并发时性能略有下降,因此在本例中,部署的可能是单流版本。在生产中,下一步将是遵循最适合并行化的下一段代码,并重新启动
APOD。
结尾
在本文中,我们介绍了如何在NVIDIA Nsight 系统中设置、使用和解释 Python
代码的分析结果。C 和 C++
代码的分析方法非常相似,事实上,大多数资料都使用了 C 和 C++ 示例。
我们还展示了分析如何让我们捕捉错误并测试程序性能,确保我们引入的功能确实提高了性能,如果没有,原因何在。
最后, 我所有代码都是放在了 Colab 的一个文件中,其中:
1 2 argv = sys.argv0 ]]
这一段是因为要兼容 Jupyter Notebook 才写的,否则如果只是执行 Python
文件的话可以去掉。
另外,如果你不太明白怎么讲这个文件拆成独立的Kernels.py,
run_v1.py, run_v2.py, run_v3.py,
可以去这里下载源码:
链接: https://pan.baidu.com/s/1gqN3Cza0h4oZoPvzJqKMaw?pwd=euvg
提取码: euvg --来自百度网盘超级会员v8的分享